В прошлых уроках мы полностью познакомились с CQL и тем, как он помогает нам управлять Cassandra, мы увидели основные операции с пространствами ключей и таблицами в Cassandra, мы смогли применить их для создания начальной структуры в базе данных, Тем не менее, существует значительное количество передовых концепций, которые нам необходимо знать, чтобы получить максимальную отдачу от Кассандры.
Эти концепции или характеристики, чтобы их вызывать каким-либо образом, позволяют нам достигать различных функциональных возможностей в наших таблицах, предоставляя нам диапазон возможностей, значительно больший, чем у остальной части другой базы данных NoSQL .
Типы данных
Ранее мы создали несколько таблиц и использовали значения, такие как текст или дата, для наших столбцов, но это не все, что есть в CQL, давайте посмотрим, какие типы данных мы имеем для наших операций:
ASCII
Строка символов типа US-ASCII.
BIGINT
Целочисленное значение длиной 64 бита.
капля
Тип данных, выраженный в виде шестнадцатеричного числа в командной консоли CQL, дополнительно не имеет проверки и основан на произвольных байтах.
логический
Классический тип логических данных, где их значения могут быть истинными или ложными.
счетчик
Счетчик - это новый тип данных для тех, кто прибывает из реляционного мира и указывает, что он распределен по 64 битам.
десятичный
Другой тип данных, который мы можем распознать, который дает нам десятичную точность для нашей информации.
двойной
Тип данных с плавающей запятой, но основанный на 64 битах.
поплавок
Как и предыдущий, это тип данных с плавающей запятой, но основанный на 32 битах.
инет
Этот тип довольно специфичен и в то же время очень полезен и позволяет нам хранить символьную строку IP-адреса, он поддерживает формат IPV4 и IPV6 .
ИНТ
Классический тип целочисленных данных, который поддерживает числа до 32 бит.
список
Другой тип данных, который дебютирует в Cassandra и позволяет нам хранить упорядоченную коллекцию элементов.
карта
Лайк-лист - это другой тип новых данных, который позволяет нам хранить ассоциативный массив, что очень полезно для разработки приложений.
набор
Подобно типу списка данных, он хранит коллекцию элементов, но без определенного порядка.
текст
Сохраните закодированную строку символов.
отметка времени
Тип данных, который хранит дату и время, закодирован как 8-байтовое целое число.
varint
Тип точности данных для произвольных целых чисел.
Как мы видим, существует много типов данных, которые мы можем распознать, если мы пришли из реляционного мира, подобно другим, которые мы увидим впервые и которые выделяют Кассандру из других баз данных.
Свойства таблицы
В Cassandra у нас есть не только типы данных для наших таблиц, благодаря CQL мы можем назначать таблицы в свойствах нашей базы данных, которые очень нам помогают в задачах обслуживания и разработки, давайте посмотрим, что у нас есть.
Кэширование
Это свойство дает нам оптимизацию кеш-памяти. Уровни, доступные для этого свойства, являются всеми или всеми, keys_only или только keys, row_only или только строками и ни один или ни один. Все параметры весьма полезны, однако row_only следует использовать с осторожностью, поскольку Cassandra помещает в память значительный объем данных при использовании этого параметра.
комментарий
Опция, присутствующая в реляционной модели и используемая администраторами или разработчиками для создания заметок и выделения важных деталей в таблицах.
уплотнение
Это свойство позволяет определить стратегию управления минимальными таблицами, они могут быть следующих типов: первый SizeTiered, который запускается, когда таблица превышает предел, преимущество использования этой стратегии состоит в том, что она не снижает производительность записи, однако Одним из недостатков является то, что он иногда использует вдвое больший размер данных на диске, что приводит к снижению производительности чтения. Вторая стратегия - LeveledCompaction, и она работает на разных уровнях с течением времени, связывая таблицы с более длинными, что приводит к довольно хорошей производительности чтения.
компрессия
Это свойство определяет, как информация будет сжата. Мы можем выбрать, чтобы получить производительность в скорости или пространстве, где больше скорость, меньше места на диске экономится.
Gc_grace_seconds
Это свойство определяет время ожидания для удаления информации из надгробий. По умолчанию 10 дней.
Populate_io_cache_on_flush
Это свойство по умолчанию отключено, и мы должны активировать его, только если ожидаем, что вся информация помещается в кэш-память.
Read_repair_chance
Очень интересное свойство, которое указывает число от 0 до 1, 0, определяющее вероятность восстановления информации, когда кворум не достигнут. Значение по умолчанию составляет 0, 1.
Replicate_on_write
Это свойство применяется только к таблицам типов счетчиков . Если определено, реплики записывают все затронутые реплики, игнорируя указанный уровень согласованности.
Тогда мы уже знаем, что у нас есть, как на уровне типов данных, так и на уровне свойств. Настало время применить некоторые вещи, изученные к нашим таблицам в Cassandra .
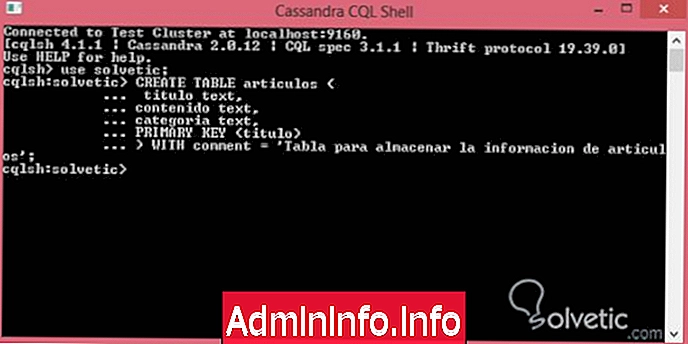
Сначала мы создадим простую таблицу, к которой мы применим свойство comments, давайте посмотрим синтаксис, который мы будем использовать для него:
CREATE TABLE article (текстовое название, текстовое содержание, текстовая категория, PRIMARY KEY (title)) WITH comment = 'Таблица для хранения информации о статье';Мы открываем нашу командную консоль CQL и создаем нашу таблицу с упомянутым свойством, давайте посмотрим, как она выглядит:

Как мы знаем, командная консоль не возвращает ничего, кроме того, что ошибки нет, но если мы хотим увидеть эти изменения, мы можем перейти в наш OpsCenter и убедиться, что все прошло правильно:
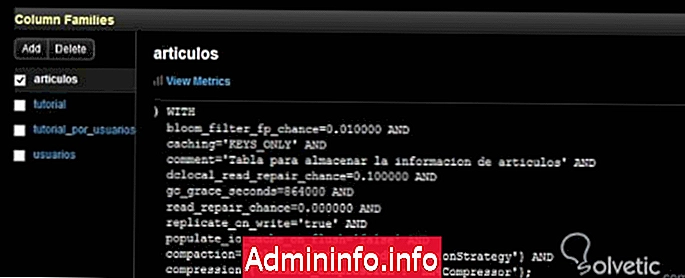
Как мы видим, мы можем видеть наш комментарий и другие свойства с их значениями по умолчанию. Важно отметить, что определение остальных свойств в Cassandra довольно простое, как мы могли видеть из предыдущего примера, используя синтаксис WITH, мы можем сделать это без каких-либо проблем.
Сжатие и уплотнение
Мы собираемся сделать еще один пример, где мы собираемся определить свойства сжатия и сжатия, но для этого важно знать, что у них есть ряд подопций для их использования, давайте посмотрим на сжатие, которое мы должны знать:
Sstable_compression
Эта опция указывает используемый алгоритм сжатия, его значения: LY4Compressor, SnappyCompressor и DeflateCompressor .
Chunck_length_kb
Таблицы сжаты блоками. Более длинные значения обычно обеспечивают лучшее сжатие, но увеличивают размер информации для чтения. По умолчанию эта опция установлена на 64 кб.
Управление параметрами сжатия может привести к значительному увеличению производительности, в том числе многие реализации Cassandra имеют эти значения по умолчанию, но для их совершенствования необходимо использовать эти значения. Посмотрим теперь, что мы должны знать для уплотнения:
Включено
Определите, будет ли свойство работать в таблице, хотя по умолчанию во всех свойствах включено сжатие .
класс
Здесь мы определим тип стратегии для управления таблицами.
min_threshold
Это значение доступно в стратегии SizeTiered и представляет минимальное количество таблиц, необходимое для запуска процесса уплотнения. Это определено по умолчанию в 4.
max_threshold
Доступен таким же образом в стратегии SizeTiered и определяет максимальное количество таблиц, обрабатываемых при сжатии. Это определено по умолчанию в 32.
Это некоторые из наиболее важных опций для этих свойств, важно отметить, что для определения этих опций мы должны использовать синтаксис JSON, чтобы быть действительным, поэтому давайте рассмотрим пример включения этих двух свойств:
CREATE TABLE properties_table (int id, имя текста, текстовое свойство, номер varint, PRIMARY KEY (id)) WITHcompression = {'sstable_compression': 'DeflateCompressor', 'chunk_length_kb': 64} ANDcompaction = {'class': 'SizeTieredCompactionStrategy', 'min_threshold': 6}; Как мы видим, мы изменили тип сжатия, и мы определили размер для него. Кроме того, для сжатия мы оставили обычную стратегию со значением класса, и мы определили min_threshold как 6, увеличив таким образом значение по умолчанию, чтобы закончить, давайте посмотрим, как это будет выглядеть, когда Мы запускаем его в нашей командной консоли: $config[ads_text5] not found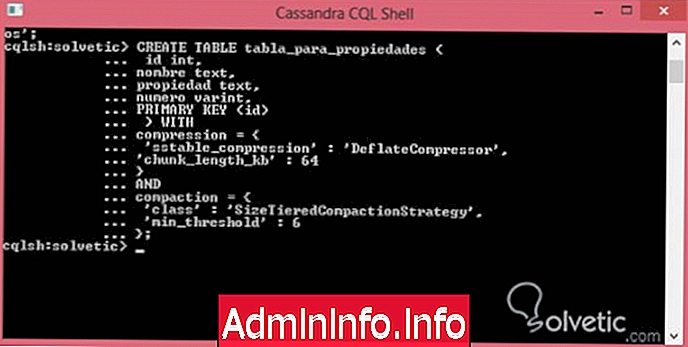
Сортировка данных в кластере
В последнем уроке мы увидели, что после определения более одного первичного ключа они создаются как ключи кластеризации и указывают способ, которым Cassandra упорядочивает информацию, по умолчанию порядок определяется в порядке возрастания и выполняется запрос в порядке убывания. Это может вызвать проблемы с производительностью, однако у Cassandra есть решение для любой проблемы, и это с помощью оператора CLUSTERING ***** BY . Давайте посмотрим, как его использовать.
СОЗДАТЬ ТАБЛИЦУ заказанных_ пользователей (текст пользователя, дата отметки времени, зарплата с плавающей запятой, текстовый отдел, текст супервизора, ПЕРВИЧНЫЙ КЛЮЧ (пользователь, дата)) С КЛАСТЕРИЗОМ ***** BY (дата DESC);Давайте запустим наш синтаксис в командной консоли и посмотрим, как он выглядит:
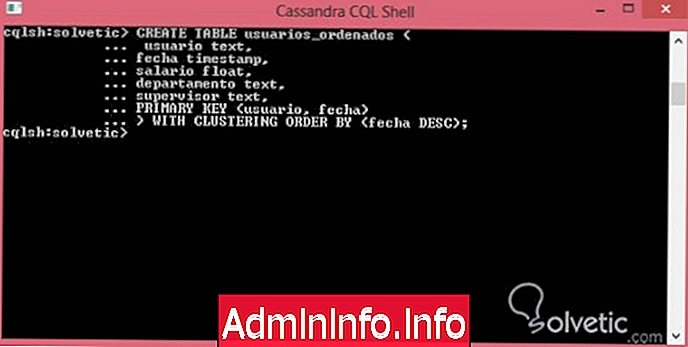
Как мы могли видеть, решить эту проблему было довольно просто с помощью простой строки, но самое главное, что мы смогли расширить наши знания об управлении таблицами в Cassandra, которая завершила этот урок, где мы рассмотрели все, что Нам нужно знать для оптимального создания таблиц в Кассандре .
СТАТЬИ