Сегодня я собираюсь показать вам, как перемещаться по ссылкам на странице с помощью Python ( очистка веб-страниц ), это может быть очень полезно для автоматического отслеживания содержимого на веб-сайте и не нужно делать это вручную. В программе, которую я привожу, каждая ссылка получается при чтении html, вы можете изменить программу для поиска определенного контента и показывать только те ссылки, в которых вы заинтересованы.
Вы также можете выполнить очистку веб-страниц, используя файл robots.txt или файлы Sitemap, которые есть на веб-сайтах.
примечание
Показанный код работает в Python 3.x, если вы хотите запустить его в версии 2.x, вам придется внести небольшие изменения.
Тогда я оставляю код:
очередь на импорт import urllib.request import re from urllib.parse import urljoin def download (page): try: request = urllib.request.Request (page) html = urllib.request.urlopen (request) .read () print ("[ *] Загрузить OK >> ", страница) кроме: print ('[!] Ошибка загрузки', страница) return None return html def crawlLinks (page): searchLinks = re.compile ('] + href = ["'] ( . *?) ["']', re.IGNORECASE) queue = queue.Queue () queue.put (page) посещения = [страница] print (" Поиск ссылок в ", страница) while (queue.qsize ()> 0): html = download (queue.get ()), если html == нет: продолжить ссылки = searchLinks.findall (str (html)) для ссылки в ссылках: link = urljoin (page, str (link)) if (link не в гостях): cola.put (ссылка) visit.append (ссылка), если __name__ == "__main__": trackLinks ("http://www.solvetic.com") Первое, что мы делаем, это импортируем необходимые библиотеки для регулярных выражений (re), чтобы использовать очередь (queue), делать запросы и читать страницу (urllib.request) и для построения абсолютных URL-адресов из Базовый URL и другой URL (urljoin).Код разделен на 2 функции
скачать
Это помогает нам загрузить HTML страницы. Это не нуждается в подробном объяснении, все, что он делает - это запрос на нужную страницу, читает ее html, если все идет хорошо, он показывает сообщение OK Download, и если он не показывает, что произошла ошибка (здесь мы могли бы показать информацию об ошибке), в конце возвращает чтение html или None.
rastrearEnlaces
Это основная функция и будет проходить через каждую ссылку. Давайте объясним это немного:
- Мы создаем переменную с регулярным выражением, которое помогает нам находить ссылки в html.
- Мы начинаем переменную типа очереди с начальной страницы, это поможет нам сохранить ссылки в «порядке», который мы обнаружили. Мы также инициируем переменную типа списка с именем посещения, которую мы будем использовать для сохранения ссылок при их посещении, это делается для того, чтобы избежать бесконечного цикла, представьте, что страница x ссылается на страницу y, а это в свою очередь на страницу x все время будем вставлять эти бесконечные ссылки.
- Ядром функции является цикл while, который будет выполняться, пока в очереди есть ссылки, поэтому мы проверяем, что размер больше 0. В каждом проходе мы берем ссылку из очереди и отправляем ее в функцию загрузки, что html вернет нас, мы сразу же найдем ссылки и проверим, посетили ли мы его, если нет, добавим его в очередь и в список.
примечание
Может показаться, что список остался, но из очереди мы будем удалять и удалять ссылки, поэтому проверка будет неправильной, возможно, ссылка, которую мы посетили некоторое время назад, и ее больше нет в очереди, но она будет в список
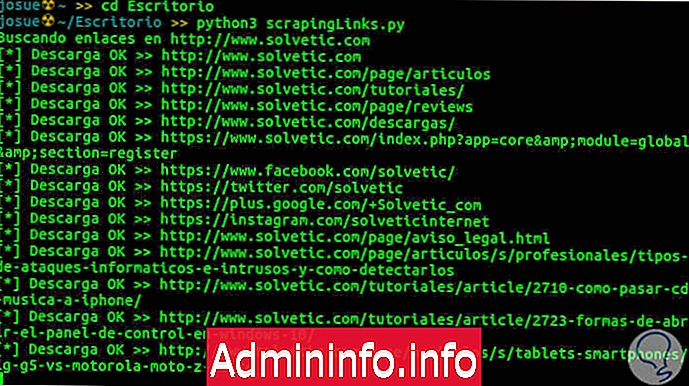
Последняя часть кода, уже находящаяся вне функций, будет отвечать за выполнение кода. На следующем изображении вы можете увидеть снимок бегущего кода, отслеживая решение.

Если вы хотите, чтобы вы могли помочь себе с библиотекой для Python, которая называется BeautifulSoup, с ней вам будет очень легко обращаться, я рекомендую это сделать.
Если вы хотите код, вот почтовый индекс:
RecorrerEnlaces.zip 646 байт 281 скачиваний

- 0
СТАТЬИ